
鼎茂科技助力银行客户,应对含400+微服务的核心系统运维挑战
鼎茂全面分布式新核心系统智能运维解决方案,旨在帮助各类规模的金融机构客户,在核心金融系统向全面分布式架构...
案例应用解决方案 >AIOps for IT - 鼎茂全面分布式新核心系统智能运维解决方案
鼎茂全面分布式新核心系统智能运维解决方案,旨在帮助各类规模的金融机构客户,在核心金融系统向全面分布式架构转型的过程中,快速应对技术变化带来的运维挑战。
方案深度结合了鼎茂的云原生、大数据处理、指标体系、AI分析、分布式全链路追踪、智能监控和告警,以及根因分析等技术,帮助金融客户快速升级智能运维体系,在无需增加人力和技能成本的同时,实现“实时发现异常,快速定界问题,辅助决策处置”,全面保障核心系统的运维SLA。
目前该解决方案已在多家采取分布式新核心系统的银行客户环境中落地。本文的客户故事为某城市商业银行的实践案例,该行在核心系统升级后,微服务和黄金指标数量均有百倍级别的增量,鼎茂解决方案有效帮助客户实现了运维体系的升级,为金融机构客户构建面向新核心系统的运维体系提供了有效的价值参考。
案例背景 >
随着移动互联网及大数据时代的到来,各类金融业务快速增长,传统集中式核心系统的处理模式已不能满足多样化的计算需求。金融机构开始加速技术升级,推动核心系统向能够快速扩缩容量和性能的全面分布式架构演进。
在此背景下,案例客户银行作为数字化发展较早的一批金融机构,已经完成了从集中式向分布式架构转型的核心系统升级。随着转型后系统复杂度的增加,客户亟需一套完整且专业的智能运维体系,可适配分布式核心应用系统架构,保障新核心系统的稳定运行。

01
需求分析
01.1 面临的问题
该行转型后的新核心业务系统由400余个微服务,上千个容器实例,500余个服务器节点,结合分布式数据库构建而成。相比传统架构,仅业务黄金指标就翻了400倍,整体运维数据体量日增超过10TB。
·微服务数量激增,黄金指标翻了400倍
基于统一规则的传统监控不再适用
需要为每一个微服务和指标进行量身定制的监控规则
在案例客户场景中微服务达到400多个,相比传统架构,仅业务黄金指标就翻了400倍。同时,由于各个微服务业务行为的多样性,基于统一规则的传统监控不再适用,监控规则需要为每一个微服务和指标进行量身定制,且依赖加大资源投入也不能完全解决该问题。
·微服务、容器、链路等新运维对象加入,使得告警风暴更易发生
原有的告警事件运维模式不再适用
需要对大量的并发重要告警进行关联和收敛
由于微服务架构引入了包括微服务、容器、链路在内的新的运维对象类型,这使得故障场景的告警风暴更容易发生。在面对海量原始告警事件的告警风暴场景下,多发地重要告警往往缺乏关联性,使得原有的告警事件运维模式不再适用。
·多服务间共用IT中间件,故障难以快速定位
传统应用架构的故障分析方法不再适用
需要综合分析事件、对象和数据之间复杂关系和影响
新核心系统采用微服务架构,交易由服务与服务间的调用构建而成。由于多个服务共用IT中间件,经常遇到由于中间件故障而导致多个服务同时发生异常的情况。与传统应用架构中各业务独立使用中间件相比,在新核心的分布式环境里,缺乏分析问题的显著突破口,根因定位的难度和复杂度加剧。
01.2 项目建设目标
鉴于以上的各种挑战,客户希望能够建设一套完整且专业的、适配分布式核心应用系统架构的智能运维体系,实现以下需求:
·微服务全链路追踪分析
实时动态捕获微服务间调用拓扑,并对微服务故障报错进行溯源,解决故障分析滞缓,业务影响扩大的问题。
·业务指标、IT组件基础指标智能监控
建立智能化的、自适应的异常监控策略,解决无法做到海量指标监控全覆盖的痛点。
·告警折叠与告警关联收敛
有效降低告警风暴期告警的数量,并对若干重要告警形成关联,以告警故障场景维度进行统一分析。
·智能故障分析定位
当分布式新核心业务系统发生故障产生告警风暴后,快速定位故障可能的原因,缩小排查范围,并给出异常对象的处置建议。
02
解决方案及思路
02.1 建设思路
该建设方案基于鼎茂ARCANA数智底座,结合ARC-IMC(对象指标中心)、ARC-ADP(数据治理平台)、Di-Logger(日志分析平台)、Di-Monitor(智能监控中心)、Di-Alert(智能告警中心)、Di-RCA(根因分析中心)等技术和场景能力,构建了一套面向分布式新核心系统的智能运维平台,具备分布式全链路跟踪、智能监控、智能告警收敛以及故障定位分析能力,并为客户提供统一的管理门户。
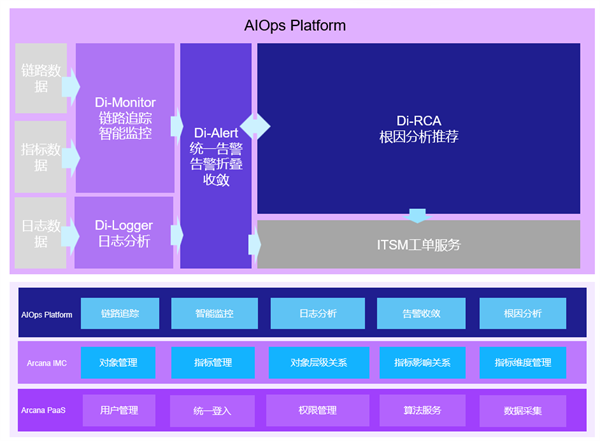
02.2方案实施
Step1 部署云原生数智底座ARCANA(含ARC-ADP、ARC-IMC)
-采用被动接收+主动轮询,结合容器Agent技术,实现400+微服务系统运维数据的实时流式采集;
-结合ARC-IMC对象指标中心,建立了对象指标体系,覆盖从交易-业务-服务-基础组件-基础设施全域运维对象指标;
-以对象指标体系为核心,完成“指标数据治理、链路日志数据解析、告警数据标准化”等数据处理。
Step2 搭载智能监控功能模块(Di-Monitor、Di-Logger)
-通过Di-Monitor链路追踪模块,即时采集调用链数据,并计算分布式核心业务系统的动态调用拓扑。结合机器学习算法,对调用特征和微服务之间的调用指标进行异常检测,生成业务交易层面的告警异常信息;
-通过Di-Monitor IT组件监控模块,结合基于动态基线的异常检测和多维告警规则组合配置能力,实现IT组件指标监控和异常告警;
-利用Di-Logger的日志分析能力对日志实施异常检测,并实现日志的智能监控。
Step3 搭载智能告警功能模块(Di-Alert)
-由Di-Alert承接告警统一、告警压缩、告警关联收敛的主要能力。对海量告警进行关联收敛,以告警摘要的形式对关联告警进行通知和播报。
Step4 搭载根因分析功能模块(Di-RCA)
-编排(指标多维下钻、调用链溯源分析、对象影响关系定位、指标时空因果关系推断、外部关联分析等)根因定位分析原子算法,强化根因分析能力;
-根据分析、定位故障对象,界定故障影响范围,形成根因报告能力。
03
项目成果
03.1 解决了 大规模分布式系统的数据治理 挑战
客户核心系统转为分布式架构后,应用层监控依赖微服务调用链,且资产长期处于动态变化中,难以将运维对象和监控指标高效地结合并管理。
鼎茂解决方案在获取例如CPU负载、内存使用量等技术指标的同时,在交易流中嵌入标签,记录交易在不同应用和系统中执行、调用、跳转等操作的时空信息,完整描绘程序运行路径。同时依托运维对象指标中心对数据进行治理,构建了不同应用服务之间、同应用不同层级间和应用与指标间的数据模型。确保系统节点的漂移不会对数据采集、分析造成影响。
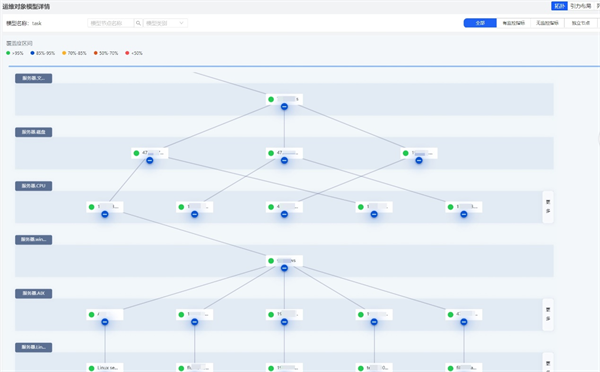
03.2解决了 海量动态运维对象的精细化监控 挑战
客户之前监控手段主要为基于指标的固定阈值告警,难以通过人工设置的方式精细地管理分布式架构下的每个运维对象,导致日常大量虚警误报的产生。
鼎茂解决方案能够对指标、调用链和日志进行一体化智能监控,并能自动分析运维对象特征,基于对历史数据的学习而生成的动态基线进行异常发现。相较于传统的固定阈值监控,能够在联机/批量业务高峰期,使用更合理的动态阈值进行监控,避免告警误报。同时也能够敏锐的捕捉到在业务高峰窗口,各项指标没有如期冲高所意味的潜在风险。在此基础上,方案提供阈值类、连续类和异常次数类告警规则设置,避免单个异常点造成的毛刺告警。
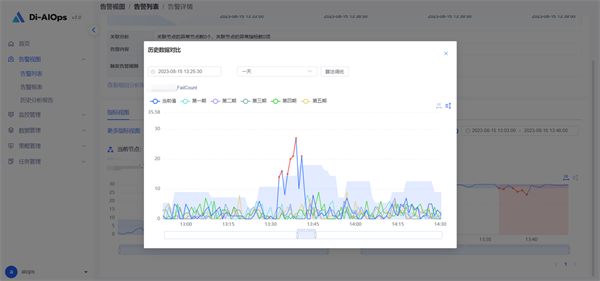
03.3 解决了 分布式对象多层级告警噪音干扰 挑战
客户核心系统原始告警峰值可达5000条每秒。这其中,重复告警和关联问题告警的冗余带来大量噪音,使运维团队为告警响应处置等工作投入大量额外资源。
鼎茂解决方案使用AI算法能力,提取告警事件语义向量序列,进行告警折叠压缩。并且根据链路调用拓扑,CMDB数据治理所得来的对象层级关系,对海量告警进行关联收敛,并对压缩后的单源告警进行层级关系聚合,推送单层与多层级聚合的告警摘要,以及影响层级、根因层级等辅助故障排查的重要信息,提升运维效率。

03.4 解决了 多组件、多节点和多数据影响的故障分析 挑战
分布式系统的故障定位通常需要运维团队熟悉全栈技术,此前客户需要借助多个监控工具,分析过程复杂,耗时较长。
鼎茂解决方案支持由告警自动触发故障根因分析,并生成RCA报告。方案采用鼎茂自研算法,结合领域知识进行故障的自动化溯源分析,整个分析过程贯穿了监控指标、调用链和日志数据,并结合了CMDB、事件工单和变更记录等信息。
在一次由于中间件节点重启导致的交易失败故障中,首先采用全景链路分析确定了发生故障的应用服务节点,同时结合多维下钻分析来判断受影响的交易请求范围。在推断出全量请求将会受到影响后,进一步分析相关基础监控指标,并使用时空关联关系分析,定位根因指标,并附以相关节点的日志信息辅助排障。
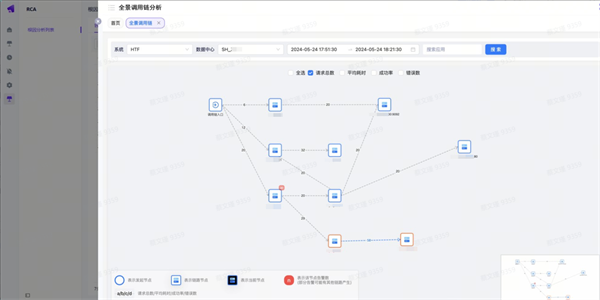
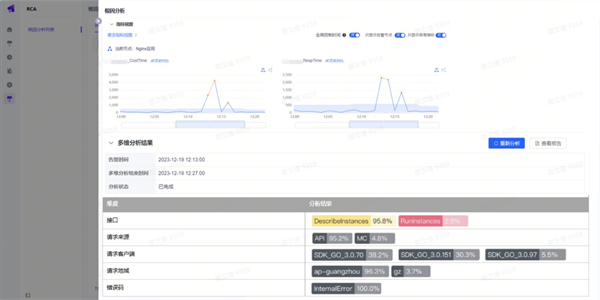
04
客户收益
鼎茂科技帮助该客户实现了快速应对分布式新核心系统的运维挑战:
通过分布式新核心业务系统智能运维平台的建设,完成了从统一监控、智能告警、根因定位的闭环分析体系。整体提高了新核心业务系统智能运维体系问题发现和问题定位的时效性。解决了分布式新核心业务系统带来的运维成本提升的痛点,并且保证了分布式新核心业务系统对外连续服务的运维水平等级。
·实现了近百万级指标的实时监控和异常检测能力。
·在告警风暴场景下实现了约85%的告警压缩收敛能力。
·形成根因定位的能力,有效地缩小了故障根源的分析范围。